URL编码
URL编码又叫百分号编码,是统一资源定位(URL)编码方式。
(1)统一资源标识符(英语:Uniform Resource Identifier,缩写:URI)是一个用于标识某一互联网资源名称的字符串。URI 是一个通用的概率,由两个主要的子集 URL (统一资源定位符,又称 百分号编码 ) 和 URN (统一资源名) 构成,URL 是通过描述资源的位置来标识资源的,URN 则是通过名字来识别资源,与它们当前所处的位置无关。
(2)URI的字符类型
URI所允许的字符分作保留与未保留。保留字符是那些具有特殊含义的字符,例如:斜线字符用于URL(或URI)不同部分的分界符;未保留字符没有这些特殊含义。百分号编码把保留字符表示为特殊字符序列。上述情形随URI与URI的不同版本规格会有轻微的变化。
RFC 3986 section 2.2 保留字符 (2005年1月)
1 | ! * ' ( ) ; : @ & = + $ , / ? # [ ] |
RFC 3986 section 2.3 未保留字符 (2005年1月)
1 | A B C D E F G H I J K L M N O P Q R S T U V W X Y Z |
URI中的其它字符必须用百分号编码。
(3)保留字符的百分号编码
如果一个保留字符在特定上下文中具有特殊含义(称作”reserved purpose”) , 且URI中必须使用该字符用于其它目的, 那么该字符必须百分号编码。百分号编码一个保留字符,首先需要把该字符的ASCII的值表示为两个16进制的数字,然后在其前面放置转义字符(“%”),置入URI中的相应位置。(对于非ASCII字符, 需要转换为UTF-8字节序, 然后每个字节按照上述方式表示.)
例如,”/“, 如果用作URI的路径成分的分界符, 则是具有特殊含义的保留字符. 如果该字符需要出现在URI一个路径成分的内部, 则三字符序列”%2F”或”%2f”就用于代替原本的”/“出现在该URI路径成分的内部.
1 | ! # $ & ' ( ) * + , / : ; = ? @ [ ] |
在特定上下文中没有特殊含义的保留字符也可以被百分号编码,在语义上与不百分号编码的该字符没有差别.
在URI的”查询“成分(?字符后的部分)中, 例如”/“仍然是保留字符但是没有特殊含义,除非一个特定的URI有其它规定. 该/字符在没有特殊含义时不需要百分号编码.
如果保留字符具有特殊含义,那么该保留字符用百分号编码的URI与该保留字符仅用其自身表示的URI具有不同的语义。
(4)受限字符或不安全字符
受限字符或不安全字符,直接放在Url中的时候,可能会引起解析程序的歧义,也需要百分号编码。
| 受限字符 | 为何受限 | 例子 |
|---|---|---|
| % | 作为编码字符的转义标志,因此本身需要编码 | encodeURI(‘%’) // “%25” |
| 空格 | Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。 | encodeURI(‘ ‘) // “%20” |
| <>” | 尖括号和引号通常用于在普通文本中起到分隔Url的作用,所以应该对其进行编码 | encodeURI(‘<>”‘) // “%3C%3E%22” |
|{}| ^[]’ |某一些网关或者传输代理会篡改这些字符。你可能会感到奇怪,为什么使用一些不安全字符的时候并没有发生什么不好的事情,比如无需对字符进行编码,前面也说了,对某些传输协议来说不是问题。
|0x00-0x1F, 0x7F|受限,这些十六进制范围内的字符都在US-ASCII字符集的不可打印区间内 | 比如换行键是0x0A|
|>0x7F|受限,十六进制值在此范围内的字符都不在US-ASCII字符集的7比特范围内| encodeURI(‘京东’) // “%E4%BA%AC%E4%B8%9C”
ASCII编码
ASCII(American Standard Code for Information Interchange:美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,由美国国家标准学会 ANSI(American National Standard Institude)于1968年正式制定。它是现今最通用的信息交换标准,并等同于国际标准ISO/IEC 646。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符)
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
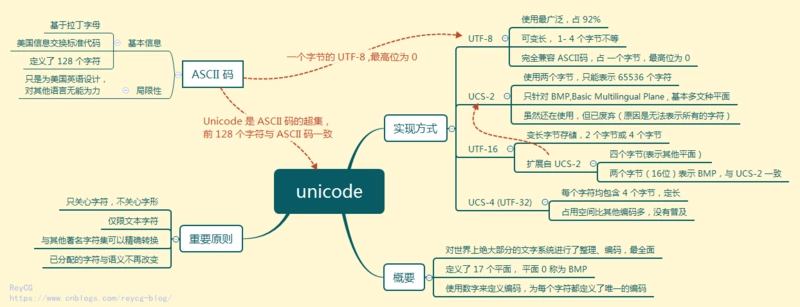
Unicode编码
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际存储传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF),Unicode的实现方式有UTF-7、UTF-8、UTF-16、UTF-32、Punycode、CESU-8、SCSU、UTF-32、GB18030等, 其中 UTF-8、UTF-16、UTF-32 使用比较广泛。
(1)UTF-8 编码
UTF-8 是使用互联网上使用最广泛的 unicode 编码方式,目前已经占有整个互联网 92% 的份额。
UTF-8 是一种变长的编码方法,字符长度从1个字节到4个字节不等。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同(Unicode 中的前 128 个字符和 ASCII 码都是一一对应的)。
| 编号范围 | 字节 |
|---|---|
| 0x0000 - 0x007F | 1 |
| 0x0080 - 0x07FF | 2 |
| 0x0800 - 0xFFFF | 3 |
| 0x010000 - 0x10FFFF | 4 |
(2)UTF-16 编码
UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。
它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。
(3)UTF-32 编码
UTF-32 对 Unicode 中的每个字符都用 4 个字节来表示。UTF-32 的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比ASCII编码大四倍。这个缺点很致命,导致实际上没有人使用这种编码方法,HTML 5标准就明文规定,网页不得编码成UTF-32。
Base64
(1)所谓Base64,就是说选出64个字符—-小写字母a-z、大写字母A-Z、数字0-9、符号”+”、”/“(再加上作为垫字的”=”,实际上是65个字符)—-作为一个基本字符集。然后,其他所有符号都转换成这个字符集中的字符。
具体来说,转换方式可以分为四步。
- 第一步,将每三个字节作为一组,一共是24个二进制位。
- 第二步,将这24个二进制位分为四组,每个组有6个二进制位。
- 第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节。
- 第四步,根据下表,得到扩展后的每个字节的对应符号,这就是Base64的编码值。
Base64索引表: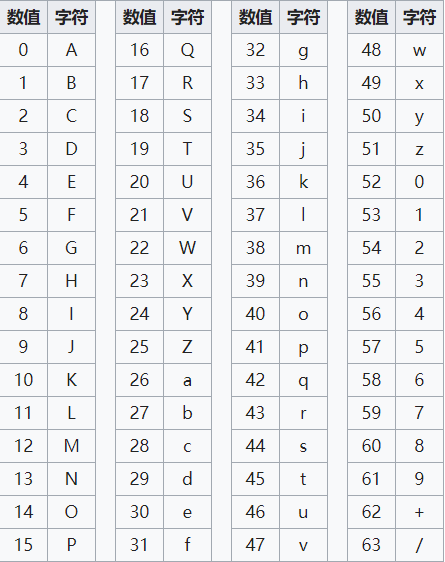
因为,Base64将三个字节转化成四个字节,因此Base64编码后的文本,会比原文本大出三分之一左右。
(2)举一个具体的实例,演示英语单词Man如何转成Base64编码。
- 第一步,”M”、”a”、”n”的ASCII值分别是77、97、110,对应的二进制值是01001101、01100001、01101110,将它们连成一个24位的二进制字符串010011010110000101101110。
- 第二步,将这个24位的二进制字符串分成4组,每组6个二进制位:010011、010110、000101、101110。
- 第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节:00010011、00010110、00000101、00101110。它们的十进制值分别是19、22、5、46。
- 第四步,根据上表,得到每个值对应Base64编码,即T、W、F、u。
因此,Man的Base64编码就是TWFu。
(3)如果字节数不足三,则这样处理:
① 二个字节的情况:将这二个字节的一共16个二进制位,按照上面的规则,转成三组,最后一组除了前面加两个0以外,后面也要加两个0。这样得到一个三位的Base64编码,再在末尾补上一个”=”号。
比如,”Ma”这个字符串是两个字节,可以转化成三组00010011、00010110、00010000以后,对应Base64值分别为T、W、E,再补上一个”=”号,因此”Ma”的Base64编码就是TWE=。
② 一个字节的情况:将这一个字节的8个二进制位,按照上面的规则转成二组,最后一组除了前面加二个0以外,后面再加4个0。这样得到一个二位的Base64编码,再在末尾补上两个”=”号。
比如,”M”这个字母是一个字节,可以转化为二组00010011、00010000,对应的Base64值分别为T、Q,再补上二个”=”号,因此”M”的Base64编码就是TQ==。